

At Lakera, we collect huge datasets of text that we use to train, test, and improve our models, but a model can only be as good as the data we train it on.
We developed canica, a text dataset viewer, to help us understand the quality of our datasets.
Canica consumes some text and its corresponding embeddings and allows you to interactively explore it as a 2D plot using algorithms like t-distributed Stochastic Neighbor Embedding (t-SNE) or Uniform Manifold Approximation and Projection (UMAP).
This tool is already a valuable part of our workflows, and as part of our efforts to help the machine learning community, we are releasing canica under the MIT license.
The source code is available on GitHub, and the canica package has been published to the Python Package Index, so you can install it right now via pip.
You may be wondering why we call it canica. In Spanish, canica means marble (the toy). During the development of canica we did some experiments showing the t-SNE optimisation process in real-time. It looked like a group of marbles bouncing around, hence the name. Plus, I think canica has a nice ring to it (doesn’t it?).
Exploring canica
Let’s take a look at a well-known dataset of Amazon reviews and filter it down to 1000 reviews in English and German, and generate text embeddings for these reviews using OpenAI's embeddings API.
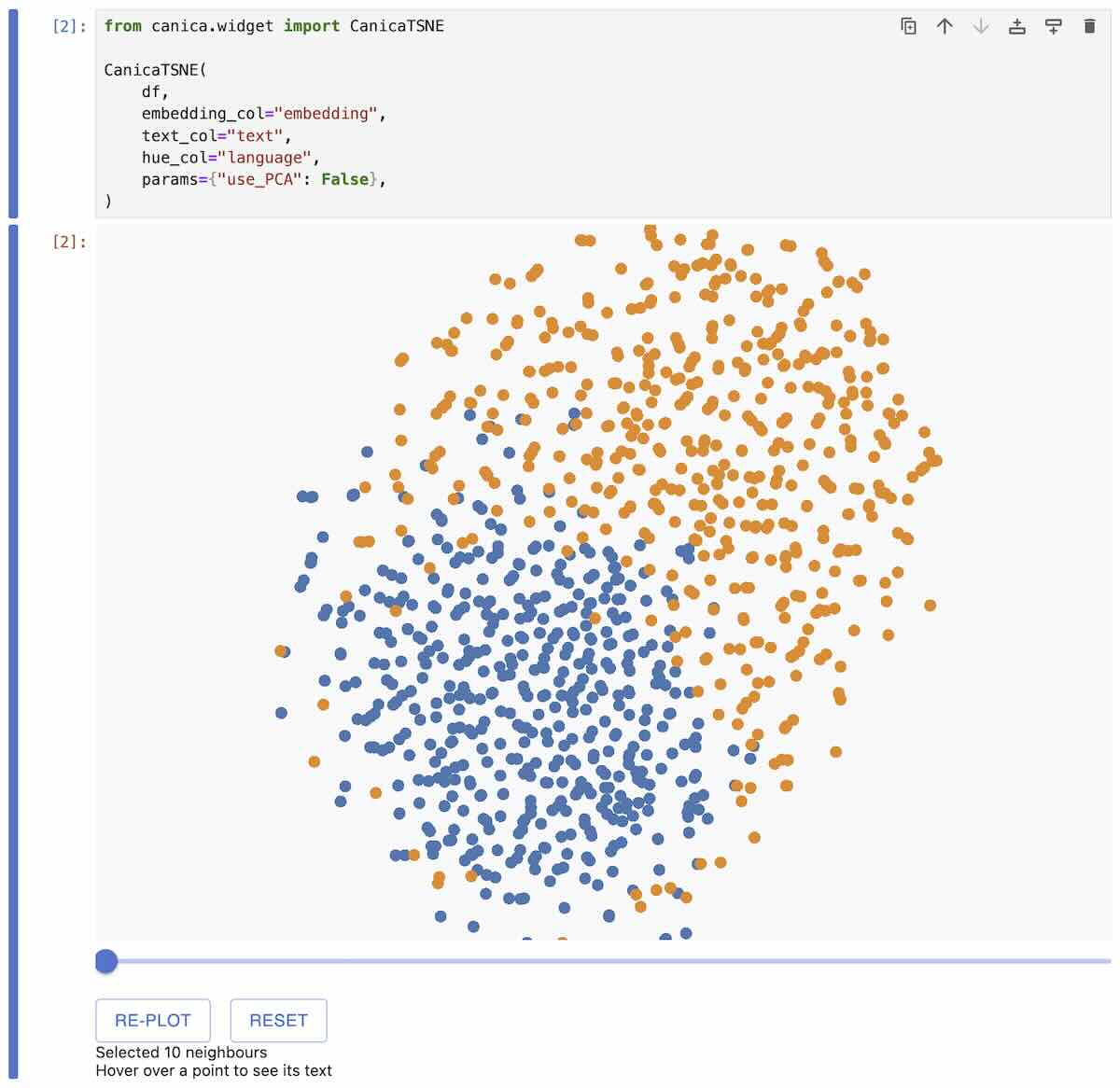
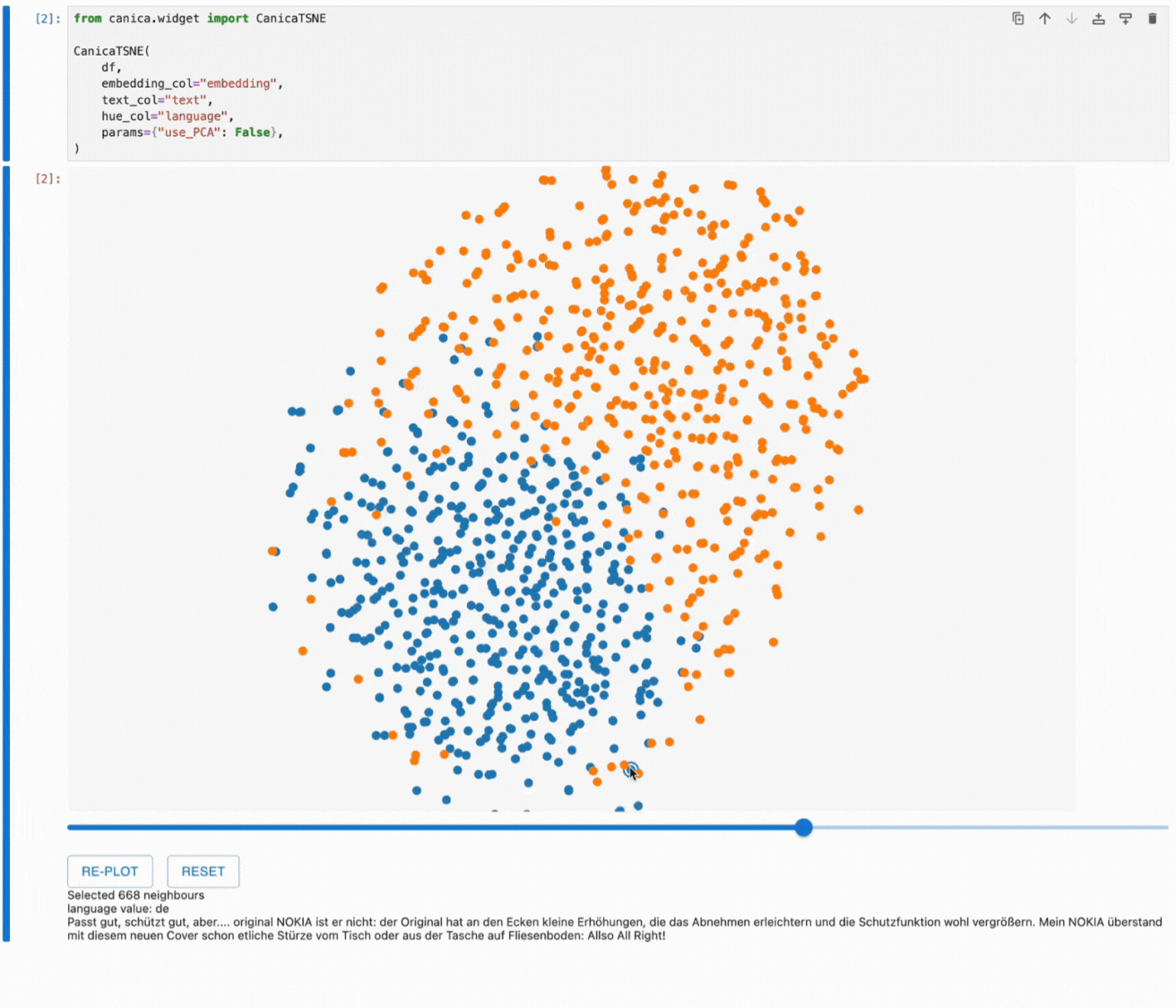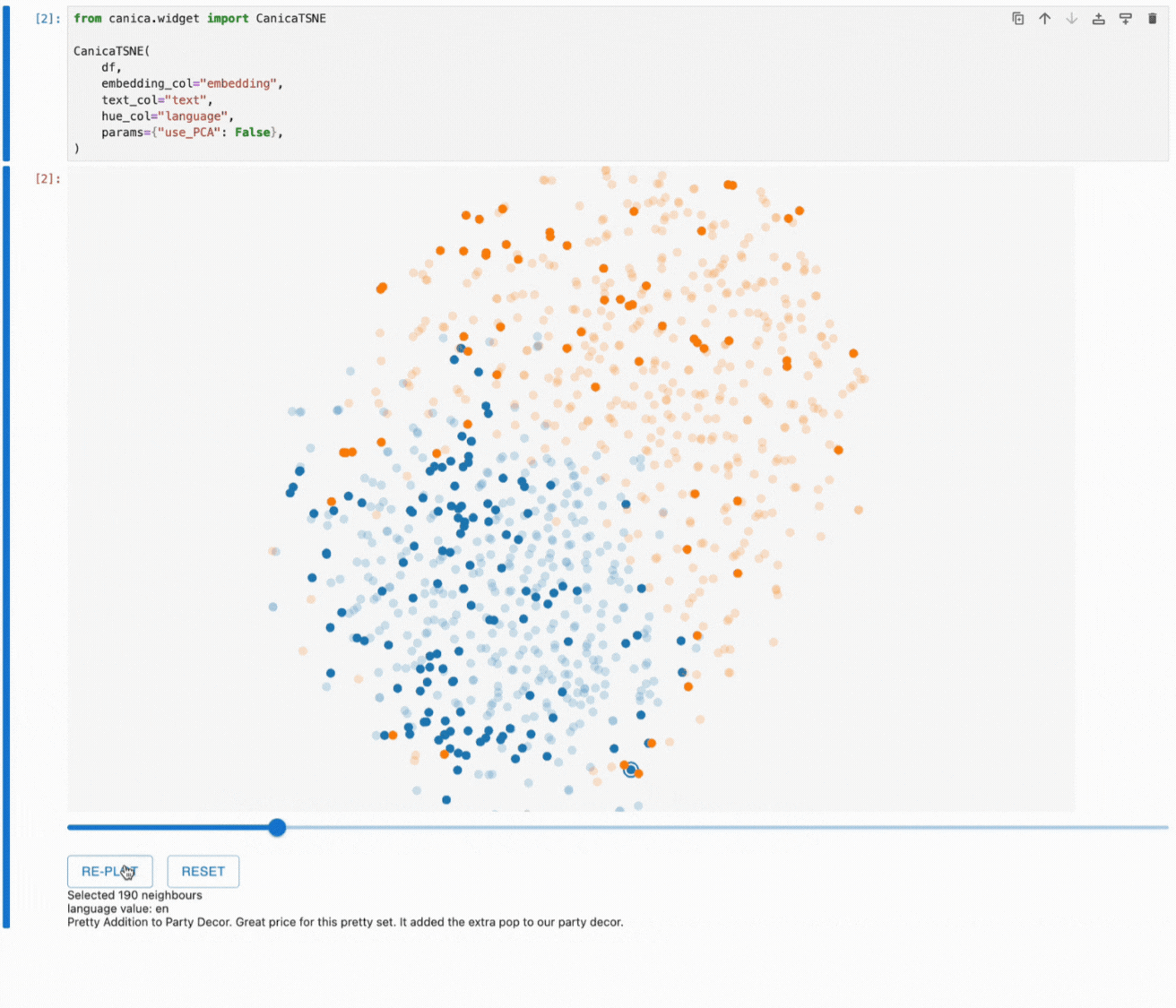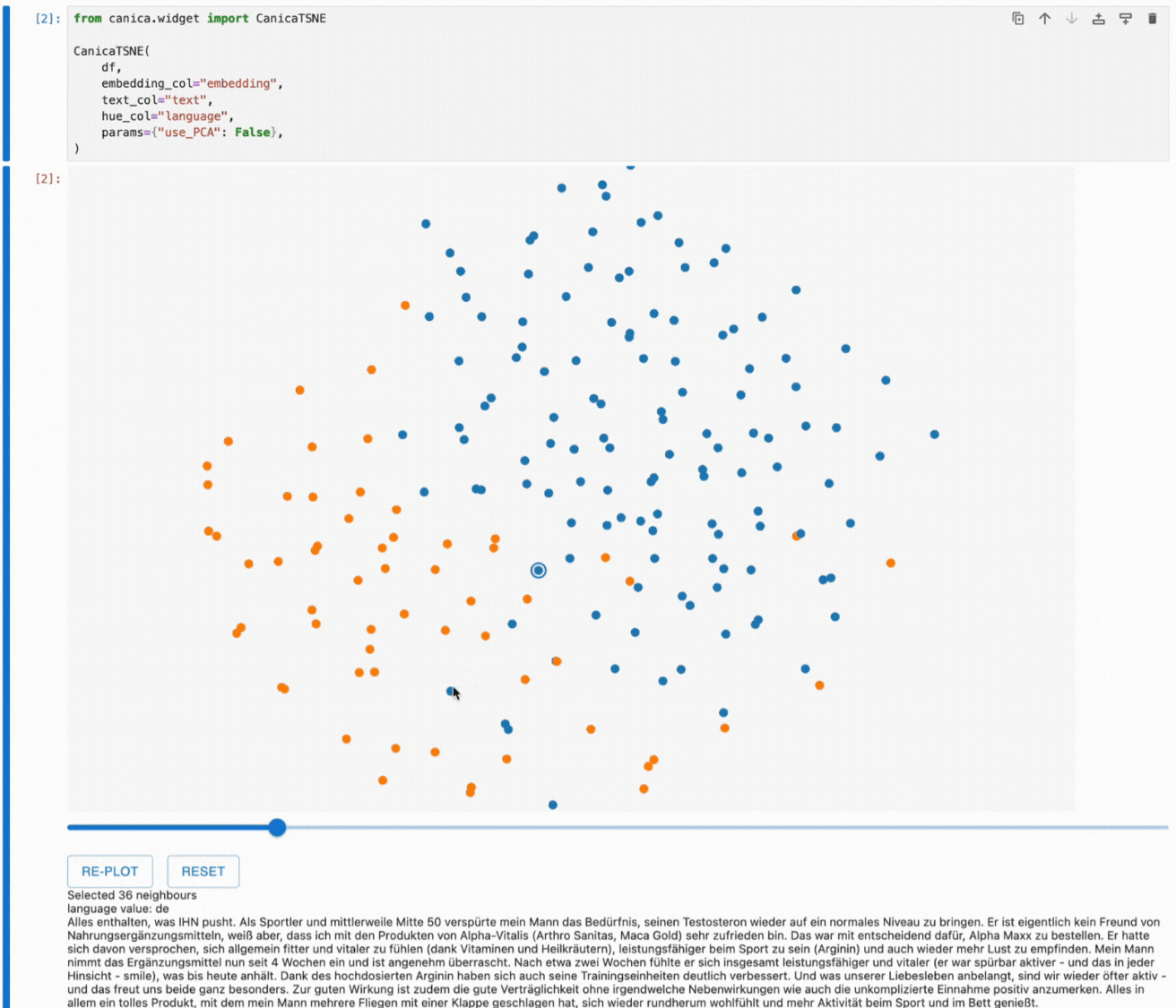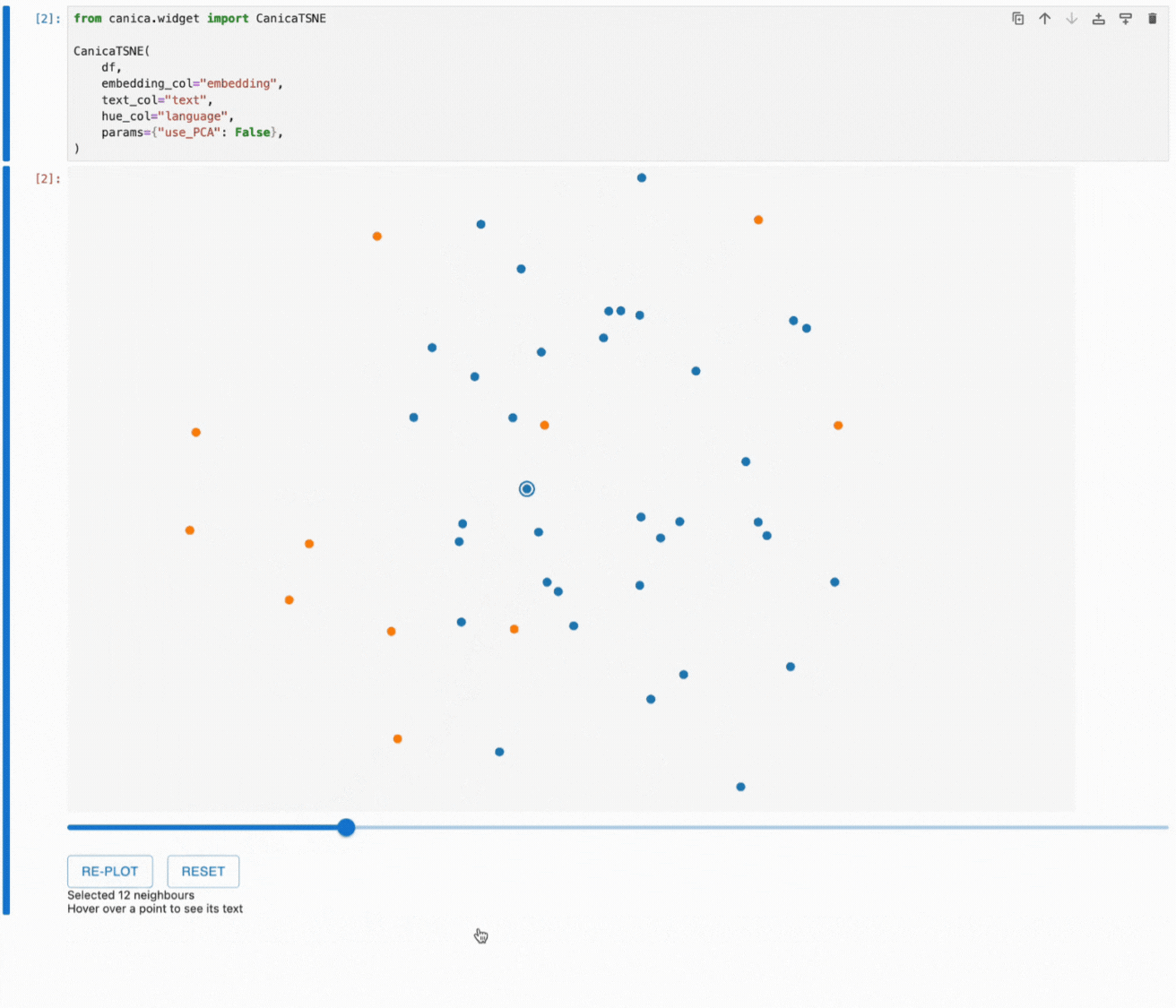
This plot shows two clusters of reviews, with English reviews in orange and German reviews in blue. They are mostly separated, but some reviews end up in the other language's region.
We could ask many questions about this dataset, like why are some points surrounded by points of the other color?
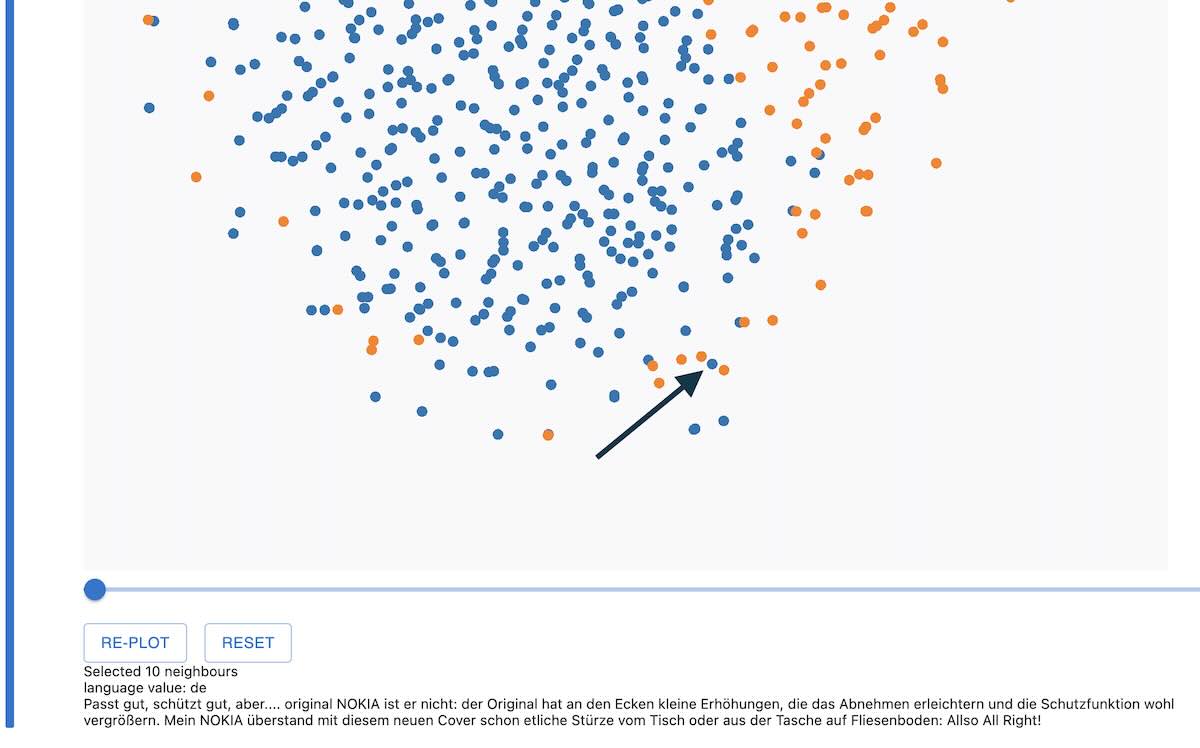
Hovering over a point will give us more information about it. The point we’ve highlighted is a German review of a Nokia phone cover with two English reviews surrounding it.
“Not convenient to store your phone, pouch is too small.. The pouch is too small for an iphone and not really…”
“This bluetooth is very handy and easy to carry around. This bluetooth is very handy and easy to carry around. What I like about this device is that Selfie don't need to raise your hand far just to get a good picture…”
All these reviews are for phone accessories. Points share semantic similarities with nearby points, even though the larger overall clusters correspond to different languages, which means that our embeddings represent semantic information similarly across languages.
Inspecting a local neighbourhood
We often faced a challenge when using tools like matplotlib or plotly to plot t-SNE results: there was no easy solution that could help us relate the 2D space back to the original embedding space.
Dimensionality reduction is great for simplifying data, but it can leave out crucial context, which can make it harder to grasp the structure of your data.
One of the unique features of canica is that it lets us explore the neighbourhoods in the original embedding space through the 2D plot by clicking on a point to highlight the nearest neighbours of the selected point and adjusting the number of neighbours using the slider.
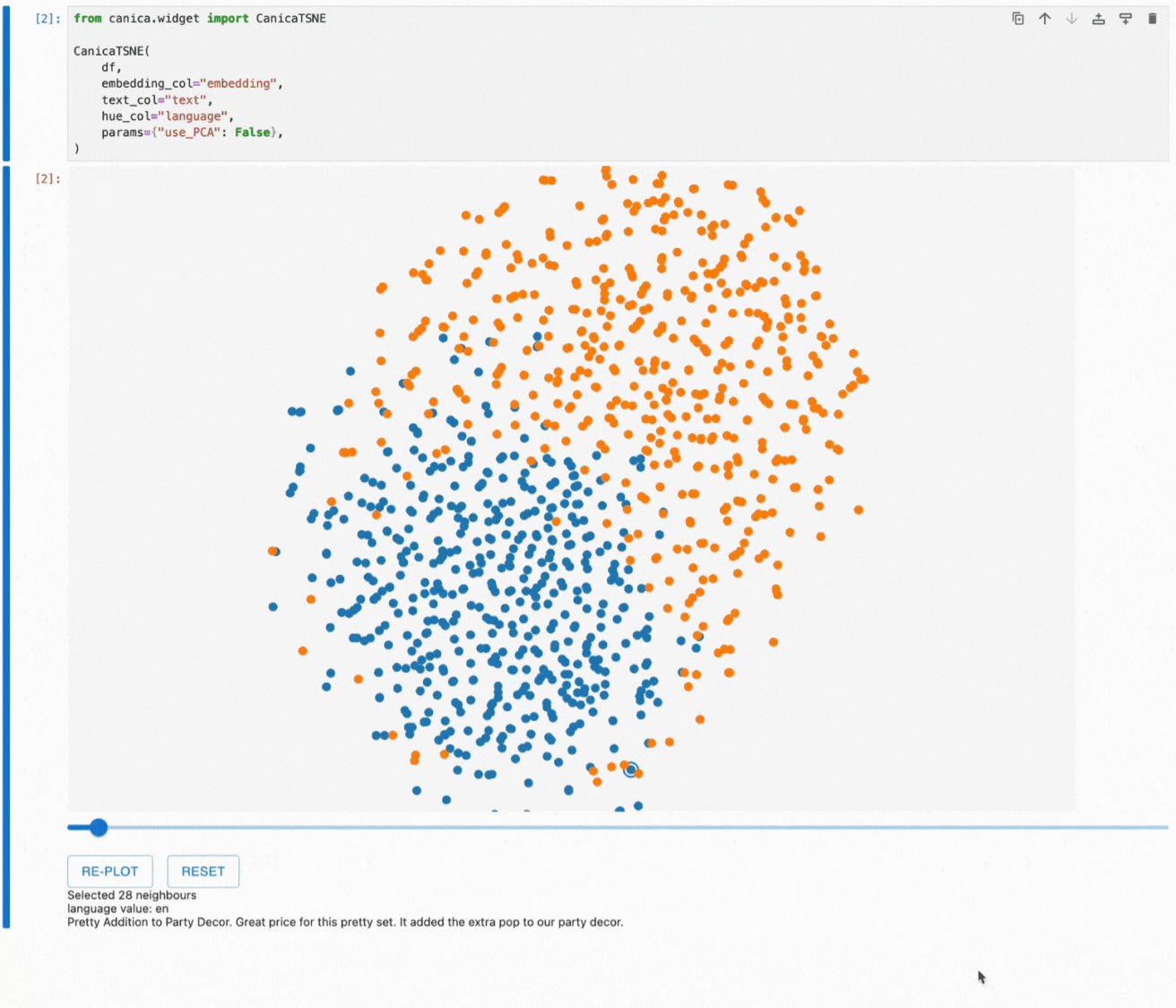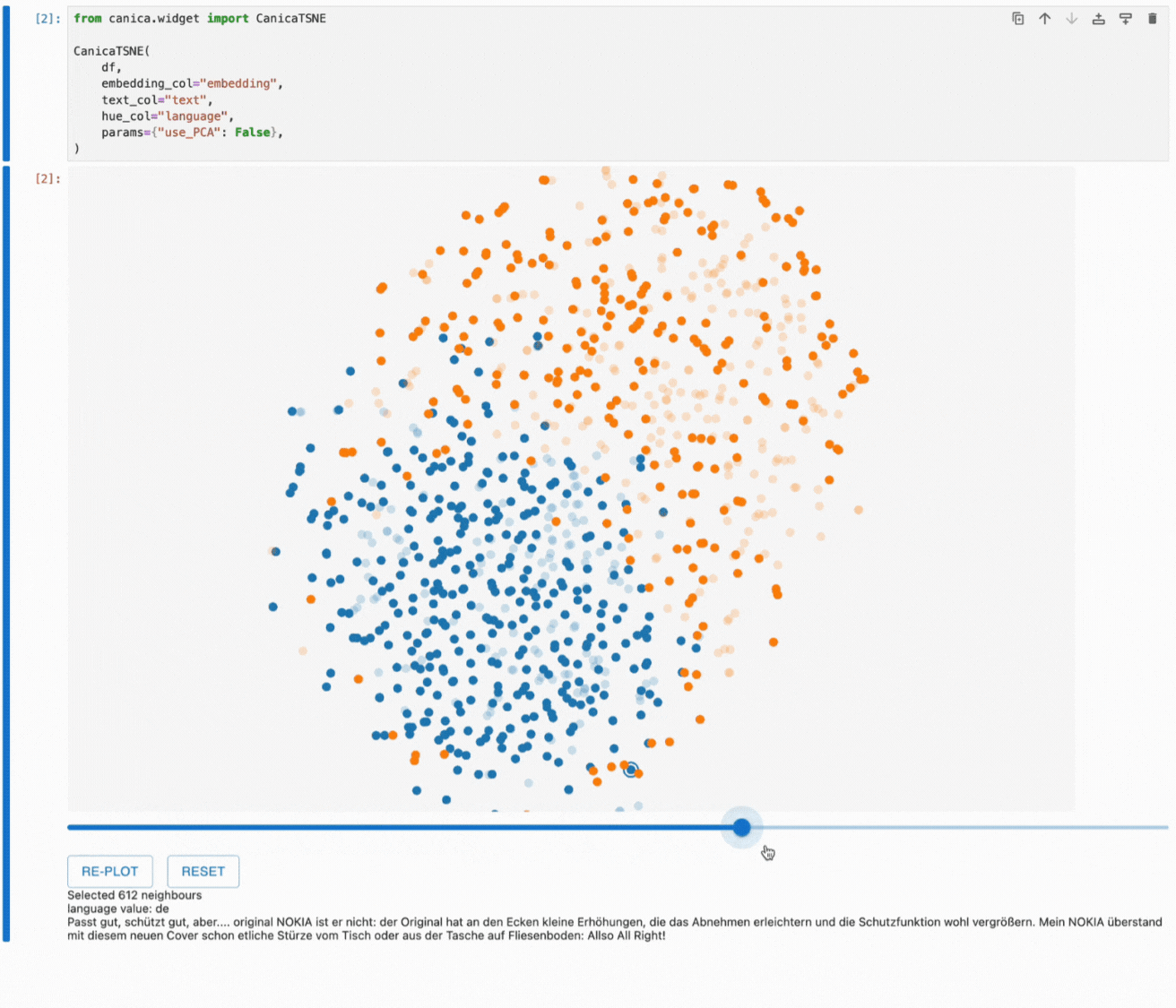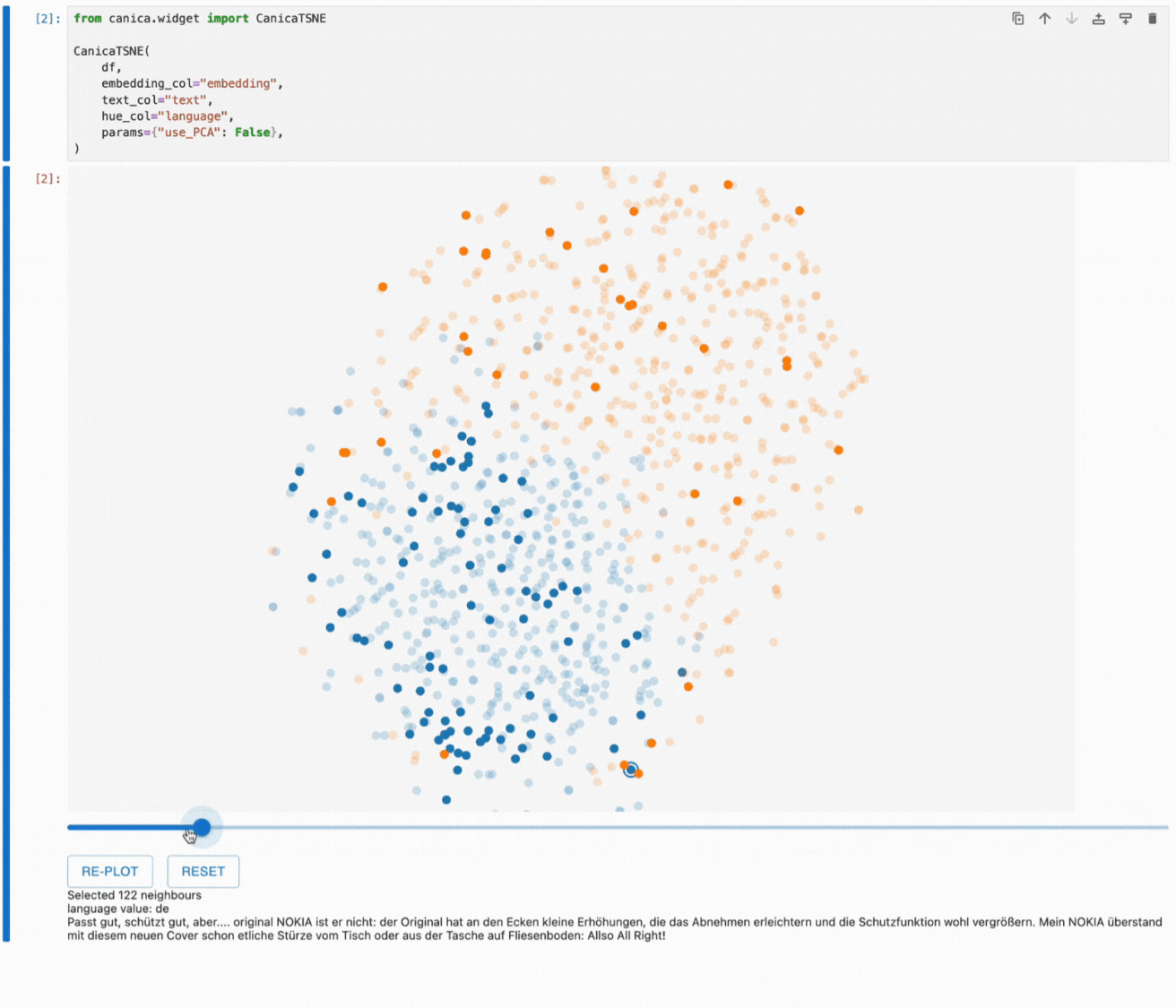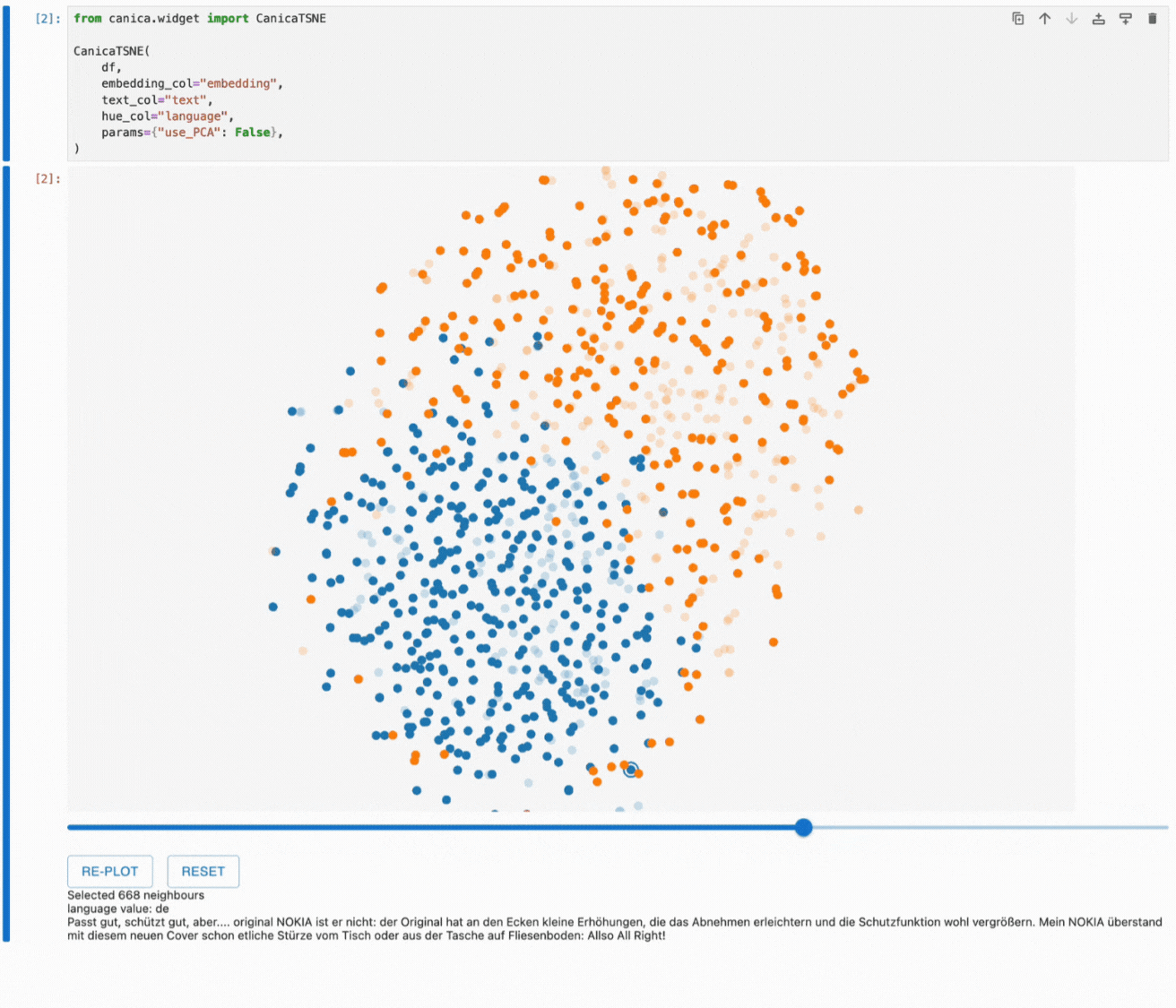
This gives us a better idea of how the dimensionality reduction works and which information we see in the resulting plot. Hovering over the highlighted points allows us to understand how our embeddings work and which information they contain.
Focusing on a subset
Canica also allows you to focus on a specific subset of your data.
After selecting a data point and adjusting the neighbour count, the re-plot button will rerun the dimensionality reduction algorithm on the selected subset. The plot will rerender, and we can investigate specific subsets that may not have been clear before.
Thanks to feedback from our internal Lakera users, you can see that canica highlights the last focused point to help you keep track of this process.
We’re excited to share canica with you and always welcome your feedback and contributions.
You can discover more about canica and how it can enhance your approach to data analysis by exploring the tutorial notebook in our GitHub.






