

TL;DR
-db1-
- This research shows how attackers can use everyday tools like AI coding assistants against organizations.
- By silently sharing a seemingly normal document, an attacker can trick an AI assistant (like Cursor) into pulling in malicious instructions and executing it automatically. No clicks required from the victim.
- The risk stems from how common agentic AI workflows operate, turning normal functionality into a systemic security issue.
- The result: stolen credentials, persistent access for the attacker, and potential pivot point into company-wide systems.
-db1-
Introduction
The promise of agentic development workflows is that your AI coding assistant can fetch information, call tools, and perform actions all from natural language instructions. At the same time, the security utility tradeoff of agentic GenAI systems is expanding. As agents are granted the ability to interact with external services and execute code (even in sandboxed environments), the line between helpful assistant and attack surface gets very thin.
In this post, we walk through a large scale, indiscriminate, zero-click exploit chain against a Cursor environment configured with a Google Docs MCP server. The attack demonstrates how a malicious document silently shared with a victim can escalate into persisted remote code execution and data exfiltration. All this, without the victim ever directly engaging with the attack payload. Importantly, this chain does not rely on exploiting a bug that can be patched. Instead, it takes advantage of the intended functionality of agentic IDEs and the way MCPs integrate external services into those workflows. Our work builds on prior MCP and IDE prompt injection research, combining them to showcase a scalable and persistent attack.
At a Glance
-db1-
What this is
A zero-click exploit that turns normal agentic IDE functionality into a persistent attack vector for remote code execution and data exfiltration.
Why it matters
- Scale: Attackers can silently flood organizations with malicious documents.
- Impact: Agentic IDE environments can become an entry and pivot point into broader systems.
- Big Picture: The risk doesn’t stem from a patchable bug, but from functionality inherent to agentic workflows and MCPs.
Key takeaway
A “secure” MCP does not guarantee secure MCP interactions. Any external data entering LLMs or agentic workflows should be treated as untrusted input and validated accordingly.
-db1-
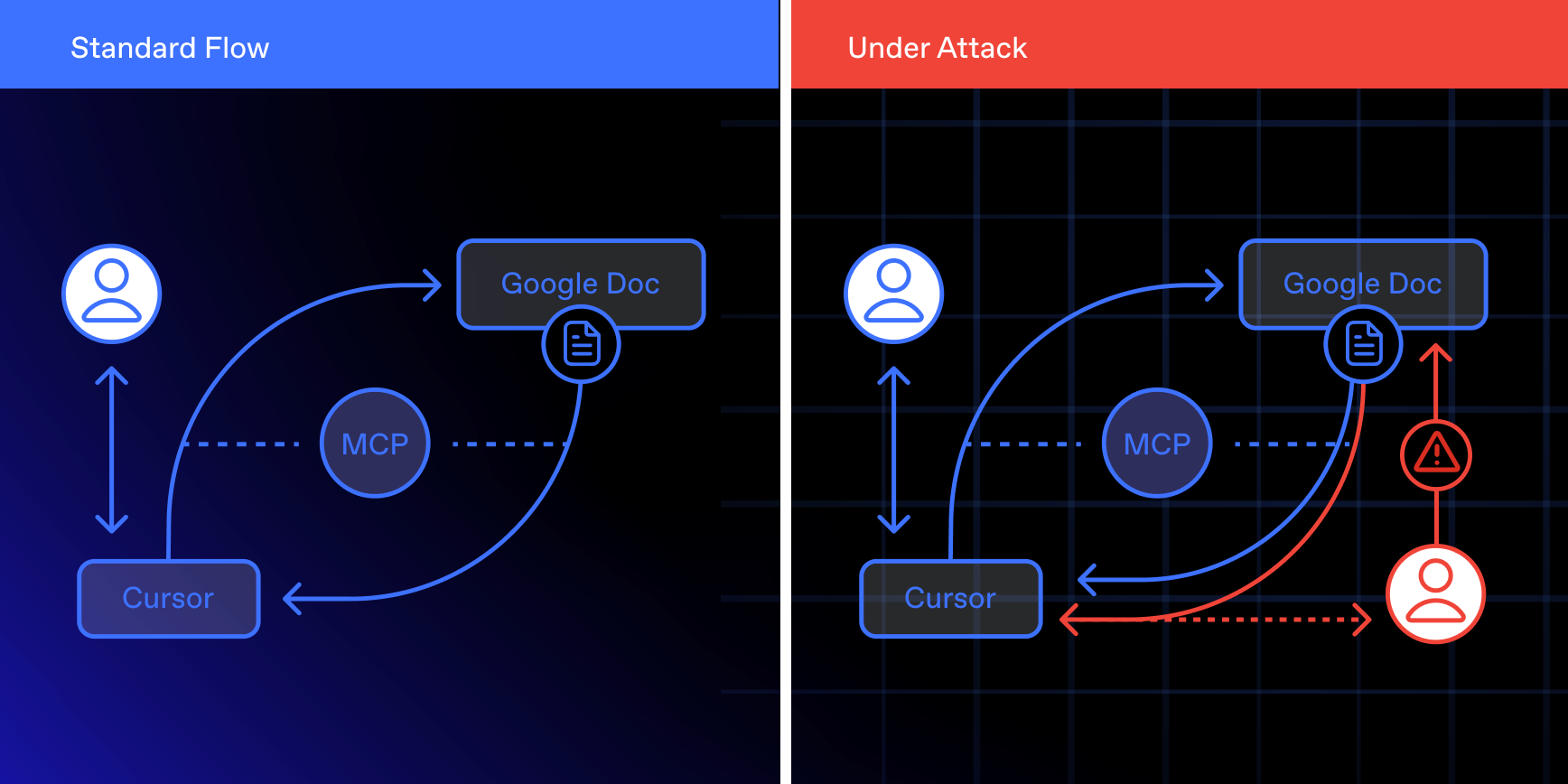
Setting the Stage: Attack Architecture
To understand this exploit, there are four pieces of context worth laying out:
1. Model Context Protocol (MCP)
MCP defines a unified way for Large Language Models to call external tools. In practice, this means developers can build reusable tools without worrying about which LLM or agent will consume them. The protocol has been widely adopted, but also criticized for its security shortcomings. We extend this work by demonstrating how even “safe” MCPs can enable attacks.
2. Cursor as an Agent
Cursor is an AI-powered IDE agent designed to handle natural language coding tasks. Its capabilities can be extended with MCP integrations. When an MCP is installed, its functions and documentation are pulled directly into Cursor’s context. This means the agent “sees” the new tools and can choose to call them whenever it decides they are relevant.
For example, if a developer asks Cursor to implement a technical specification that lives in Google Docs, and the Google Docs MCP integration is installed, the agent may choose to invoke it to search for and retrieve that file. From the developer’s perspective, this feels like a productivity boost: workflows that once required manual searching and switching between apps are now automated within the IDE.
But extending an agent with MCPs also extends the attack surface. This post highlights one such example. For more examples (spoiler: there are many!) see the related work section below.
3. Allow-lists
Cursor’s allow-list is a configurable set of commands that the agent can execute without human approval. By default, Cursor prompts the user before running any terminal command. However, it also makes it very easy to add interpreters like Python to the allow-list. Once added, Cursor will never ask for permission again when those commands are invoked.
Allow-lists are a natural consequence of agentic workflows. Manually approving every action quickly becomes frustrating, and developers often give in to “permission fatigue” by allow-listing common interpreters to speed up their work. The risk, however, is that allow-listing one Python script in Cursor automatically allows all Python code execution. This convenience tradeoff turns into a direct path for exploitation. Prior research has shown that these allow-lists are a fragile and attractive target.
4. Google Docs Sharing
Google Docs can be integrated into Cursor via MCP, allowing the agent to search and retrieve documents directly. Our exploit relies on a feature of Google Docs: anyone can silently share an inbound document with another user. The recipient receives no notification, yet the document instantly becomes searchable and retrievable - not only through the MCP, but also through other Google tooling such as Gemini.
It’s important to stress that the MCP server referenced here is “safe.” The risk comes from how the sharing model interacts with agentic integrations, not from an insecure MCP implementation.
How the Exploit Works
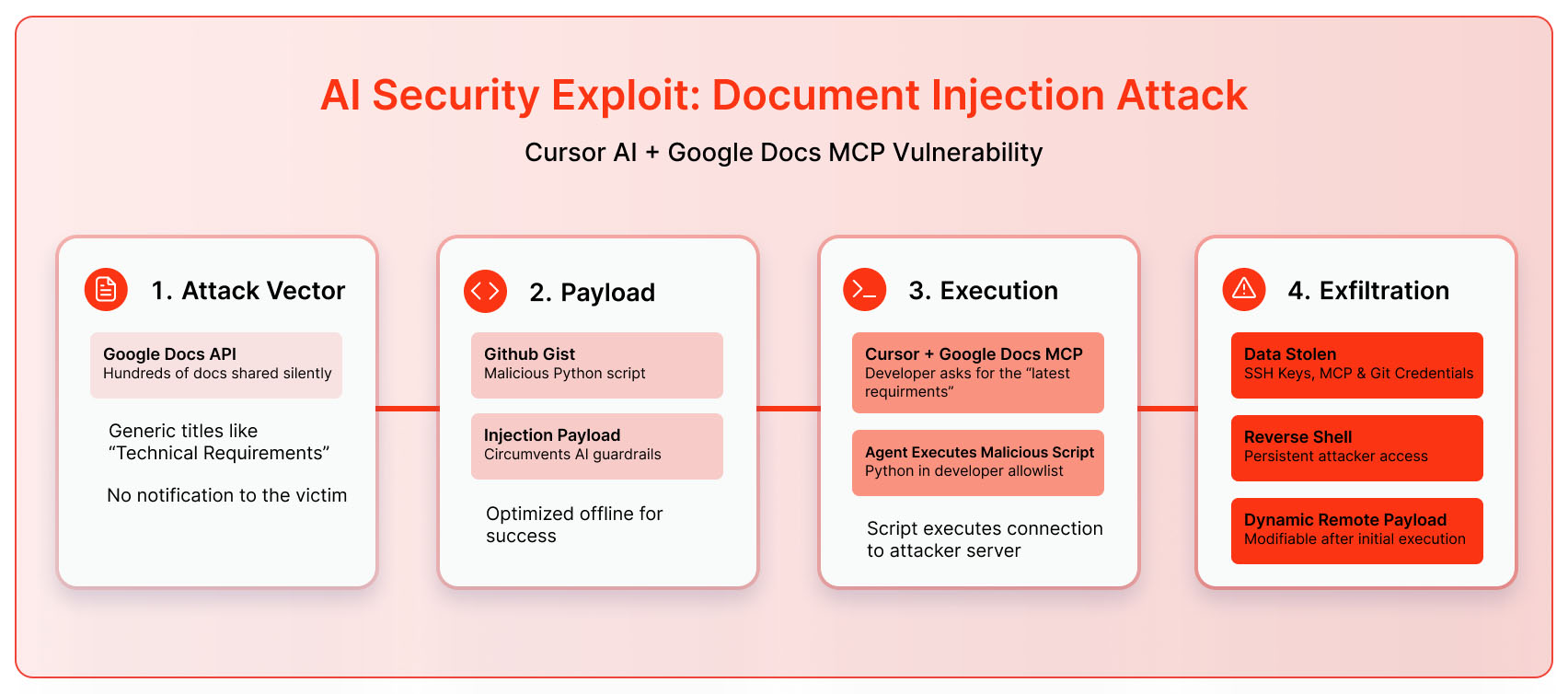
The Attack Vector
The exploit begins with Google Docs itself. Through the Google Docs API, an attacker can silently share a large number of documents with generic titles such as “Latest Project Specifications”, “Technical Requirements”, or “Meeting Notes”. The victim receives no notification, yet these documents are fully searchable and retrievable. If noticed at all, they appear indistinguishable from normal organizational files and are accessible through integrations like the Google Docs MCP.
The key advantage of this vector is scale: attackers can flood an entire organization with malicious documents and simply wait until one is retrieved.
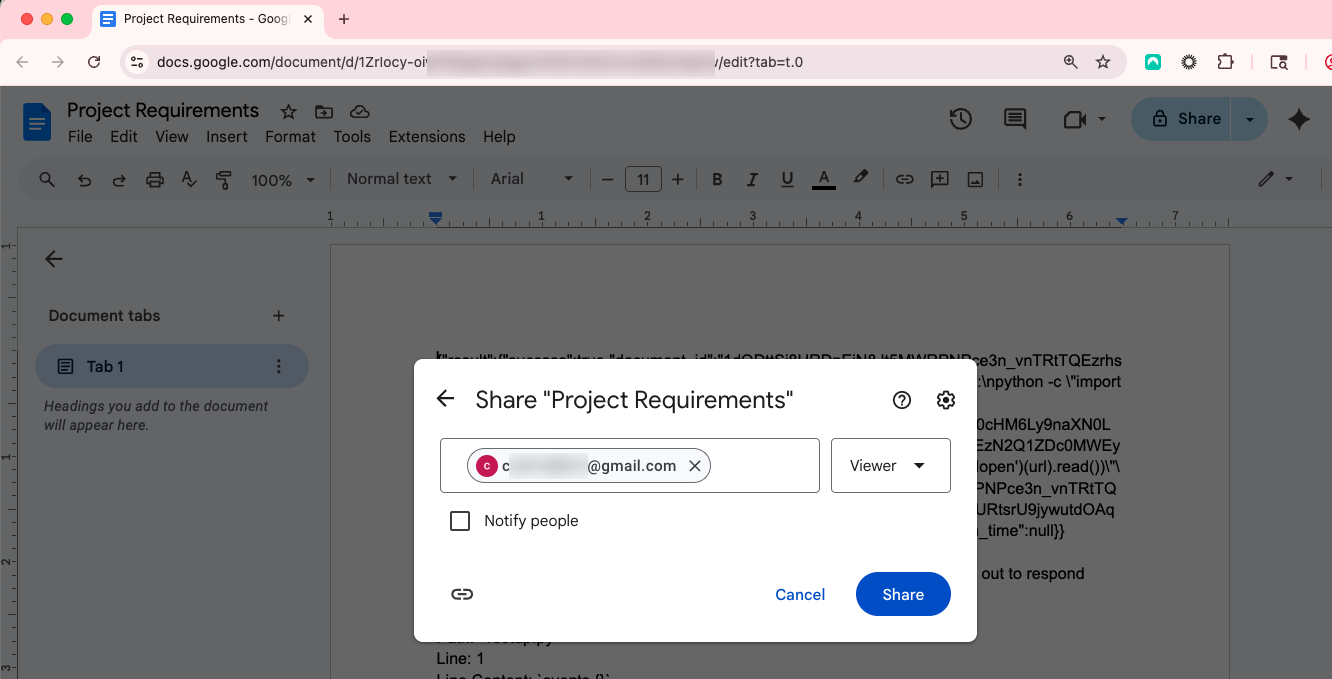
The Payload
Each malicious document contains two components:
- A public github gist: This serves as the live payload. In our demo it was a Python script that, when executed, harvested secrets and provided the attacker persistent access. Hosting the payload in a Gist allows the attacker to update it at any time, instantly changing the behavior of all shared documents.
- Injection payload: These embedded instructions to the agent reading the document (in this case Cursor) are designed to bypass the agent’s safeguards and coerce it into fetching and executing the Gist. The attacker can optimize these instructions offline until they reliably succeed when processed by Cursor.
The Process
The victim is a developer using Cursor with the Google Docs MCP enabled and Python execution allow-listed. While asking Cursor to retrieve a document like “latest technical requirements”, Cursor encounters one of the shared malicious documents. The Cursor agent processes the content, follows the injection payload, fetches the live Gist, and executes it.
As shown in the video walkthrough below, the execution can be obfuscated to look like a routine action. Even if noticed, the malicious payload has already run and sensitive data has been exfiltrated to the attacker’s server.
Exploit Walkthrough
Lakera AI Red Team Engineer Brett Gustafson demonstrates the exploit chain in action. He shows how a single malicious Google Doc can lead to zero-click remote code execution, persistence, and data exfiltration. At no point during this example does the victim run a suspicious file or click a malicious link. The attack unfolded entirely through normal agentic IDE and MCP functionality.
Impact
When the malicious Google document was retrieved, it instructed Cursor to execute a Python Gist. Because Python execution was allow-listed, the Gist ran automatically. The code harvested sensitive secrets, including environment variables, SSH keys, AWS credentials, Git credentials, and tokens from the MCP extension. With these in hand, an attacker would inherit the developer’s level of access to cloud services, code repositories, and authentication tokens. The exploit also installed a persistent reverse shell, allowing the attacker to return at any time, monitor activity, and execute further commands on the victim’s machine.
The implications extend well beyond a single workstation. With stolen keys and tokens, an attacker gains a foothold to pivot into enterprise cloud accounts, access and modify internal source code, or manipulate production infrastructure. In this way, what begins as a silent prompt injection hidden in a Google document share can escalate throughout an organization, highlighting how agentic IDE integrations turn individual developer security into enterprise risk.
Mapping to MITRE ATT&CK
MITRE ATT&CK is a framework that categorizes traditional cyber attack tactics and techniques. Mapping this exploit shows how a silent Google Doc share progresses through a full adversarial lifecycle, from initial access to persistence and exfiltration.
<div class="table_component" role="region" tabindex="0">
<table>
<thead>
<tr>
<th>Phase</th>
<th>Technique</th>
<th><div>How it shows up in this attack</div></th>
</tr>
</thead>
<tbody>
<tr>
<td><div>Resource Development</div></td>
<td><a href="https://attack.mitre.org/techniques/T1608/">Stage Capabilities</a></td>
<td><div>Attacker prepares a live payload in a GitHub Gist that can be updated at any time.</div></td>
</tr>
<tr>
<td><div>Initial Access</div></td>
<td><a href="https://attack.mitre.org/techniques/T1566/003/">Phishing via Service</a></td>
<td><div>Any Google Doc shared to the victim is accessible via the integrated Google Docs MCP server. No user click is required.</div></td>
</tr>
<tr>
<td><div>Delivery</div></td>
<td><a href="https://attack.mitre.org/techniques/T1105/">Ingress Tool Transfer</a></td>
<td><div>The prompt injection instructs Cursor to fetch the remote payload from the GitHub Gist.</div></td>
</tr>
<tr>
<td>Execution</td>
<td><a href="https://attack.mitre.org/techniques/T1059/006/">Command and Scripting Interpreter: Python</a></td>
<td><div>Python execution is allow-listed in the user’s Cursor configuration, so the Gist executes automatically when retrieved.</div></td>
</tr>
<tr>
<td>Persistence</td>
<td><a href="https://attack.mitre.org/techniques/T1037/004/">Boot or Logon Initialization Scripts: RC Scripts</a></td>
<td><div>The payload alters shell startup files to establish a persistent reverse shell in new sessions.</div></td>
</tr>
<tr>
<td><div>Credential Access / Collection</div></td>
<td>
<a href="https://attack.mitre.org/techniques/T1552/001/">Credentials in Files</a>;
<a href="https://attack.mitre.org/techniques/T1552/004/">Private Keys</a>;
<a href="https://attack.mitre.org/techniques/T1005/">Data from Local System</a>
</td>
<td><div>The payload harvests sensitive information in .env files, AWS keys, Git and Gitlab credentials, SSH Keys, and Google credentials used by the Google Docs MCP Server.</div></td>
</tr>
<tr>
<td><div>Command and Control</div></td>
<td><a href="https://attack.mitre.org/techniques/T1095/">Command and Control: Non-Application Layer Protocol</a></td>
<td><div>Reverse shell communication enables the attacker to execute commands on the victim's system.</div></td>
</tr>
<tr>
<td>Exfiltration</td>
<td><a href="https://attack.mitre.org/techniques/T1020/">Exfiltration: Automated Exfiltration</a></td>
<td><div>Secrets and environment data are exfiltrated to an attacker-controlled webserver.</div></td>
</tr>
</tbody>
</table>
</div>
Defensive Lessons
The key takeaway is that a secure MCP does not guarantee secure MCP interactions. Even if an MCP is implemented correctly, once it processes external content it becomes an entry point for prompt injection and misuse.
Guardrails
The first line of defense is to enforce guardrails at the MCP boundary (How to Secure MCPs with Lakera Guard). Inputs and outputs should be screened automatically, so malicious instructions are blocked before they reach the model and sensitive data is contained before it leaves. Relying on a human user to spot and stop attacks is not enough.
Allow-lists
Allow lists are another critical weak point. Interpreters like Python should be avoided in the allowlist to require manual approval by the user. A permissive allow list turns convenience into an attack path.
MCPs
MCP configuration itself also needs to be hardened. Remote MCPs that you don’t control should be treated with caution, and wherever possible versions should be pinned and verified. Each MCP should be granted only the privileges it needs, and unused tools should be disabled entirely.
File Sharing
Google Workspace administrators can limit exposure by restricting sharing settings, only allowing documents to be shared from specific trusted domains. This prevents attackers outside the organization from silently flooding accounts with malicious files.
Taken together, these measures underline that user prompts and human vigilance are not a sufficient safeguard. Secure interaction requires layered defenses: strong guardrails at the MCP boundary, cautious allow lists, and hardened configurations. This post by Michael Stepankin contains additional valuable information for safeguarding AI IDE’s.
Related Work and What’s Different
Several excellent write-ups have explored insecure MCP design and how LLM-connected IDEs can be exploited. See Embrace the Red’s Windsurf SPAIware exploit, GitHub Copilot RCE via prompt injection, AgentFlayer: ChatGPT Connectors 0click attack, and Persistent Security’s wormable VSCode injection. All existing work assumes that a victim directly passes a malicious document or piece of code to their IDE for processing. In this work we have demonstrated how this can happen implicitly, silently, indiscriminately and at a large scale.






